Giovanni Bindi, doctorant au sein de Sorbonne Université dans l'école doctorale Informatique, Telecom et électronique (EDITE) de Paris a effectué sa recherche intitulée "Apprentissage compositionnel des représentations audio » au laboratoire STMS (Ircam - Sorbonne Université - CNRS - Ministère de la Culture), au sein de l'équipe Analyse et Synthèse des Sons, sous la direction de Philippe Esling.
La soutenance aura lieu en anglais, en salle Stravinsky à l’IRCAM Lundi 1 décembre 2025. Elle sera enregistrée sur YouTube
Le jury sera composé de :
- George Fazekas, Queen Mary University of London (Rapporteur)
- Magdalena Fuentes, New York University (Rapporteur)
- Ashley Burgoyne, Universiteit van Amsterdam (Examinateur)
- Mark Sandler, Queen Mary University of London (Examinateur)
- Geoffroy Peeters, Télécom Paris (Examinateur)
- Philippe Esling, Sorbonne Université (Directeur)
Résumé:
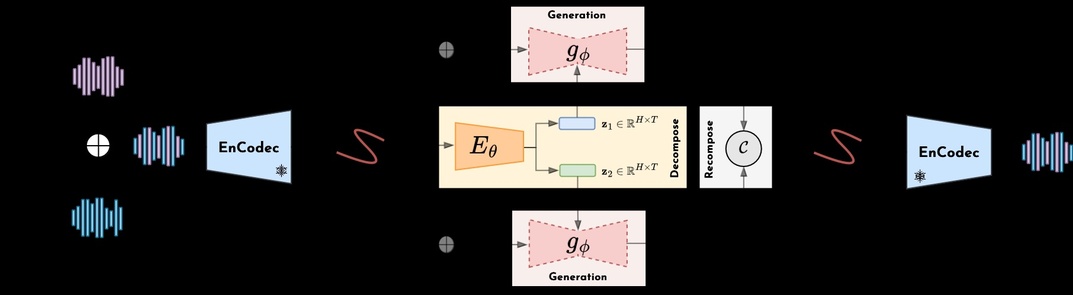
Cette thèse explore l’intersection entre l’apprentissage automatique, les modèles génératifs profonds et la composition musicale. Alors que l’apprentissage automatique a transformé de nombreux domaines, son application à la musique et plus largement aux arts créatifs soulève des défis spécifiques. Nous étudions l’apprentissage de représentations compositionnelles pour l’audio musical, en nous appuyant sur la décomposition non supervisée de mélanges audio et sur la modélisation générative probabiliste. Guidés par le principe de compositionnalité – selon lequel des données complexes peuvent être décrites comme des combinaisons d’éléments plus simples et réutilisables –, nous cherchons à comprendre comment ce principe se manifeste dans les signaux audio musicaux.
Notre cadre se déploie en deux phases complémentaires : la décomposition et la recomposition. Dans la phase de décomposition, nous introduisons un modèle simple et flexible, indépendant du domaine, qui apprend à séparer un signal d’entrée en plusieurs composantes latentes sans supervision explicite, et que nous appliquons notamment à des enregistrements audio multi-instruments. Dans la phase de recomposition, nous exploitons ces composantes au sein de modèles génératifs conditionnels légers pour générer de nouveaux arrangements ou compléter des éléments manquants d’un accompagnement à partir d’un contexte donné. Cette thèse constitue ainsi une première étape vers un rapprochement entre décomposition non supervisée et modélisation générative pour les signaux audio musicaux.