Giovanni Bindi, doctorant au sein de Sorbonne Université dans l'école doctorale Informatique, Telecom et électronique (EDITE) de Paris a effectué sa recherche intitulée "Apprentissage compositionnel des représentations audio » au laboratoire STMS (Ircam - Sorbonne Université - CNRS - Ministère de la Culture), au sein de l'équipe Analyse et Synthèse des Sons, sous la direction de Philippe Esling.
La soutenance aura lieu en anglais, en salle Shannon (à confirmer) à l’IRCAM Mardi 18 mars 2025. Elle sera enregistrée sur YouTube : https://youtube.com/live/e6SWXCkd68w
Le jury sera composé de :
- George Fazekas, Queen Mary University of London (Rapporteur)
- Magdalena Fuentes, New York University (Rapporteur)
- Ashley Burgoyne, Universiteit van Amsterdam (Examinateur)
- Mark Sandler, Queen Mary University of London (Examinateur)
- Geoffroy Peeters, Télécom Paris (Examinateur)
- Philippe Esling, Sorbonne University (Directeur)
Résumé:
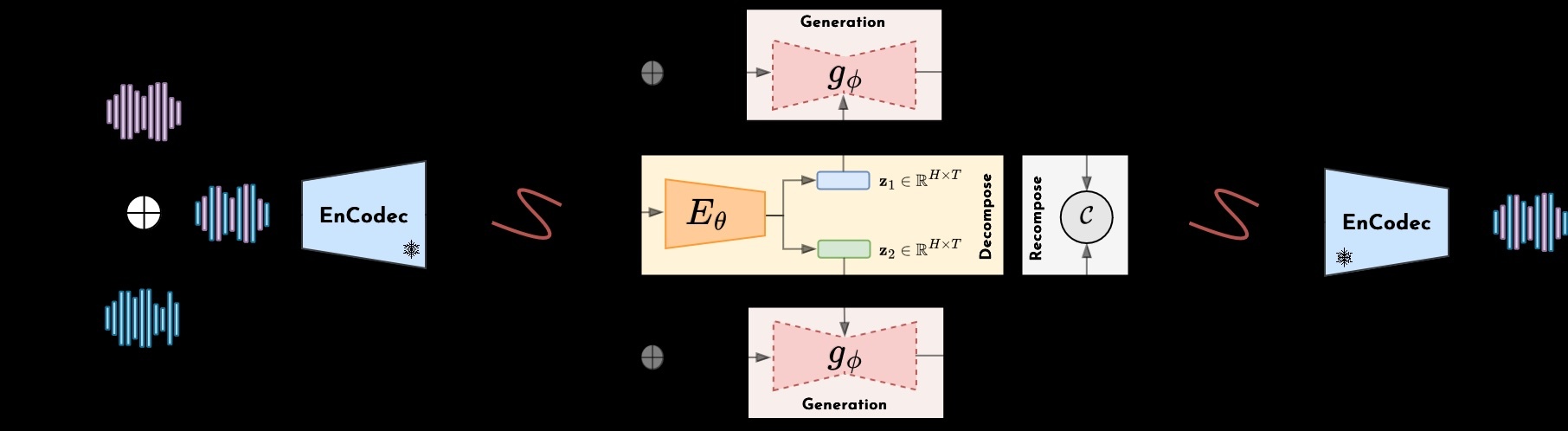
Cette thèse explore l'intersection de l'apprentissage automatique, des modèles génératifs et de la composition musicale. Si l'apprentissage automatique a transformé de nombreux domaines, son application à la musique présente des défis uniques. Nous nous concentrons sur l'apprentissage compositionnel, qui implique la construction de structures musicales complexes à partir de composants plus simples et réutilisables. Notre objectif est de fournir une première analyse de la manière dont ce concept s'applique à l'audio musical.
Notre cadre se compose de deux phases : la décomposition et la recomposition. Dans la phase de décomposition, nous extrayons des représentations significatives d'instruments à partir de mélanges polyphoniques sans avoir besoin de données étiquetées. Cela nous permet d'identifier et de séparer les différentes sources sonores. Dans la phase de recomposition, nous introduisons une approche générative qui s'appuie sur ces représentations pour créer de nouveaux arrangements musicaux. En structurant le processus de manière hiérarchique - en commençant par la batterie et en ajoutant progressivement d'autres éléments tels que la basse et le piano - nous explorons une manière flexible de générer des accompagnements. Nos résultats suggèrent que l'apprentissage compositionnel peut améliorer la séparation des sources et la génération de musique structurée. Bien que notre approche soit prometteuse, des travaux supplémentaires sont nécessaires pour évaluer son applicabilité et sa généralisation. Nous espérons que cette recherche contribuera à une meilleure compréhension des modèles génératifs en musique et inspirera de futurs développements dans le domaine de la créativité informatique.