Nils Demerlé, doctorant au sein de l’EDITE (ED 130) a effectué sa recherche intitulée « Séparation de contrôles explicites et implicites pour la synthèse neurale expressive en temps réel » au sein de l’équipe Analyse Synthèse de STMS ( IRCAM, CNRS, Sorbonne Université et Ministère de la Culture) sous la direction de Philippe Esling et co-encadré par Guillaume Doras. La soutenance aura lieu en anglais le Vendredi 31 Octobre à 11H en salle Stravinsky. Elle sera retransmise sur Youtube : https://youtube.com/live/rDfq9bwS6jk
Le jury sera composé de :
• Joshua REISS – Professor, Queen Mary University of London – Rapporteur
• Nao TOKUI – Artist and Researcher, Neutone –Rapporteur
• Anna HUANG – Assistant Professor, MIT – Examinateur
• Atau TANAKA – Professor, Goldsmiths University – Examinateur
• Tatsuya HARADA – Professor, University of Tokyo – Examinateur
• Alexandre DEFOSSEZ – Researcher, Kyutai – Examinateur
Résumé:
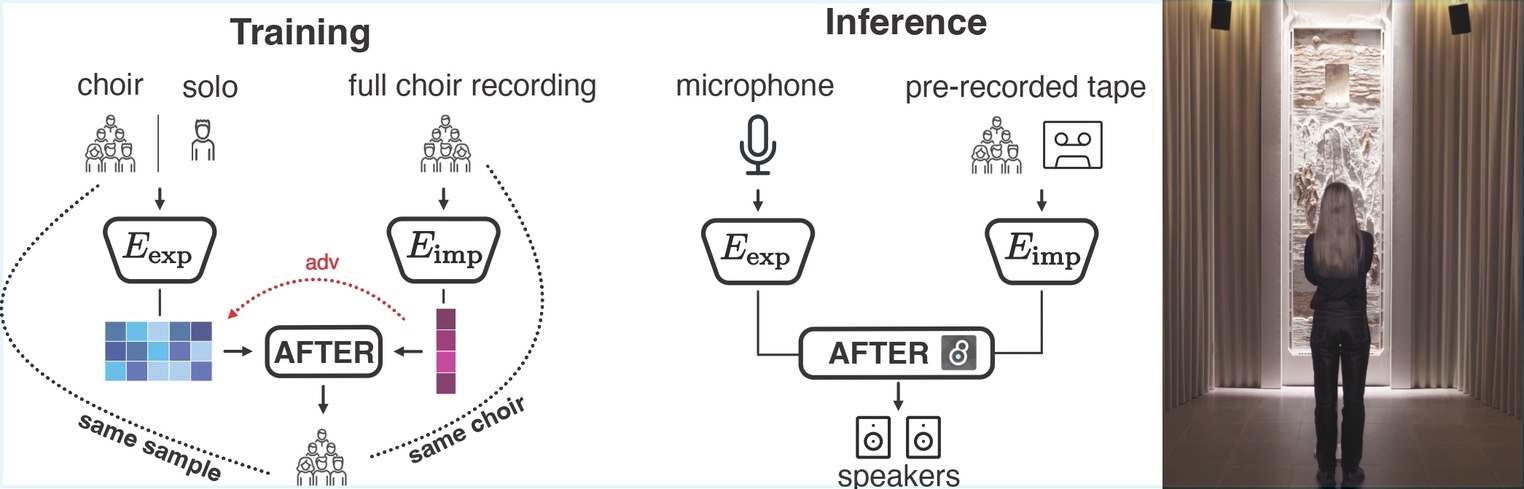
Les récents progrès en apprentissage automatique ont profondément transformé notre rapport au son et à la création musicale. Les modèles génératifs profonds s’imposent aujourd’hui comme de nouveaux instruments potentiels, capables de soutenir et d’étendre les pratiques créatives. Leur adoption reste toutefois limitée par la question du contrôle : les approches actuelles offrent soit des paramètres explicites bien définis (note, instrument, description textuelle), soit des espaces de représentation plus abstraits permettant d’explorer des dimensions subjectives comme le timbre ou le style, mais plus difficiles à intégrer dans un contexte musical.
Cette thèse vise à réconcilier ces deux paradigmes de contrôle explicite et implicite afin de concevoir des outils de synthèse audio expressifs et directement intégrables aux environnements de production musicale. Nous commençons par une étude systématique des codecs audio neuronaux, blocs fondamentaux des modèles génératifs modernes, en identifiant les choix de conception qui influencent à la fois la qualité et la contrôlabilité de la génération. Nous explorons ensuite des stratégies pour apprendre conjointement des espaces de contrôle explicites et implicites, d’abord dans un cadre supervisé, puis avec le modèle AFTER, conçu pour le cas non supervisé. Ce dernier permet notamment des transferts de timbre continus et réalistes, tout en conservant un contrôle précis des notes et du rythme.Enfin, nous adaptons ces modèles à un usage temps réel grâce à des architectures légères et streamables, et développons une interface intégrée aux stations de travail audio numériques. La thèse se conclut par plusieurs collaborations artistiques illustrant à la fois le potentiel créatif et la pertinence pratique de ces approches.