Sarah Nabi, doctorante au sein de l’école doctorale EDITE (ED130) de Sorbonne Université, a effectué sa thèse intitulée « Apprentissage de représentations adaptées pour le contrôle gestuel de la synthèse sonore par modèles génératifs profonds » au sein des équipes Interaction Son Musique Mouvement (ISMM) et Analyse et Synthèse des Sons du laboratoire STMS (IRCAM, CNRS, Sorbonne Université, Ministère de la Culture) sous la co-direction de Frédéric Bevilacqua, Philippe Esling et Geoffroy Peeters. La soutenance aura lieu en anglais le Lundi 8 Juin à 14H en salle Stravinsky. Elle sera retransmise sur YouTube : https://youtube.com/live/y3PR0oZLWV4
Le jury sera composé de :
- Rebecca Fiebrink - Professor, University of the Arts London (UAL) - Rapporteur
- Anna Huang - Associate Professor, Massachusetts Institute of Technology (MIT) - Rapporteur
- Magdalena Fuentes - Assistant Professor, New York University (NYU) - Examinateur
- Andrew McPherson - Professor, Imperial College London (ICL) - Examinateur
- Olivier Sigaud - Professor, Sorbonne Université (SU) - Examinateur
Résumé:
Ces dernières années, la synthèse audio neuronale a connu des avancées significatives, offrant des outils prometteurs pour la création musicale. Ces modèles apprennent la distribution sous-jacente des données à partir d’observations. Leur potentiel réside notamment dans leur capacité à apprendre une représentation paramétrique, appelée espace latent, utilisée pour conditionner la synthèse. Cependant, le processus d’apprentissage étant implicite, les représentations latentes sont difficiles à contrôler car abstraites et généralement de dimension trop élevée pour être directement interprétables. Les méthodes existantes reposent principalement sur le conditionnement, nécessitant de vastes ensembles de données annotées et ne prenant pas en compte la diversité des interactions. Cela souligne la nécessité d’approches centrées sur l’utilisateur afin d'étudier leur intégration dans les processus créatifs, et favoriser leur personnalisation et leur adaptabilité.
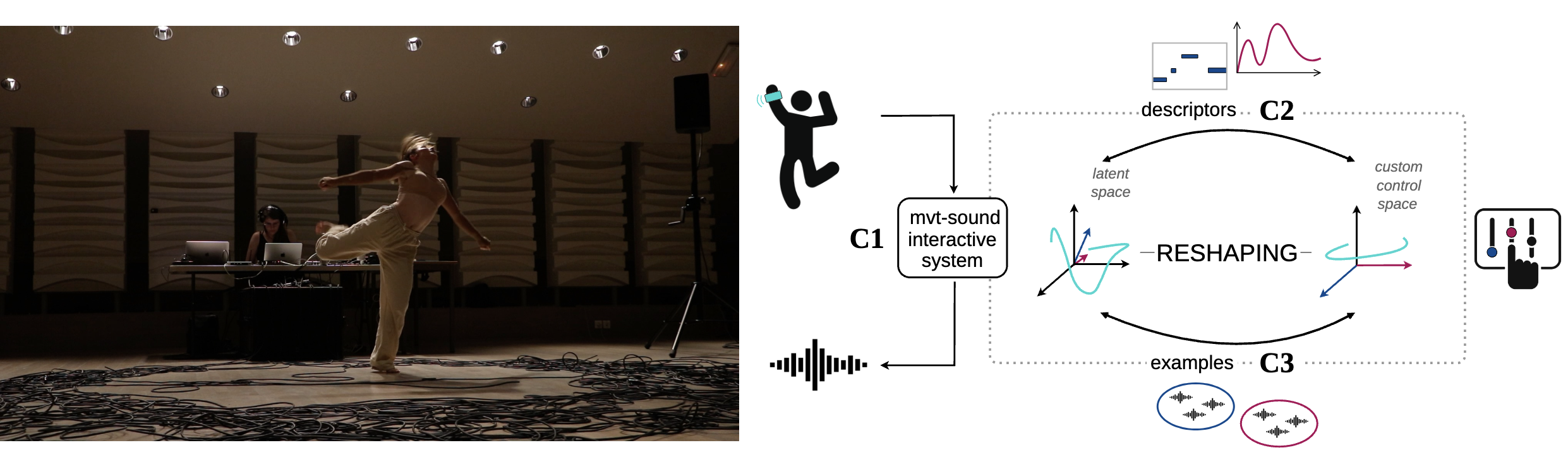
Cette thèse porte sur le contrôle gestuel de modèles de synthèse audio neuronale pour la performance musicale. Nous constatons un décalage fondamental entre l’espace gestuel de l’interprète et l’espace latent. Alors que les gestes s'inscrivent dans un espace euclidien continu de 3 dimensions, les représentations latentes évoluent dans des variétés non linéaires de grande dimension, où les caractéristiques sont fortement intriquées et difficilement interprétables. Cette disparité complique la conception des interactions et des stratégies de mapping. Bien que les interprètes puissent exploiter ces contraintes topologiques de manière créative, une autre stratégie consiste à adapter les représentations latentes afin qu’elles correspondent à des propriétés spécifiques de l’espace du geste. Cela revient à reformuler notre problème comme celui du mapping de ces paramètres latents pertinents vers un nouvel espace de contrôle adapté à l’utilisateur, préservant linéarité locale et continuité pour l’interaction gestuelle. Cependant, ces paramètres pertinents peuvent varier selon les utilisateurs et les modèles. Aussi, nous voulons permettre aux utilisateurs de définir des contrôles personnalisés à partir d’un nombre limité d’exemples. D'abord, nous établissons une collaboration art-recherche avec une danseuse. Dans le cadre d’une performance interactive danse/musique, nous explorons ces espaces latents par une approche incarnée. Nous développons un système interactif mouvement-son intégrant des modèles génératifs audio profonds et trois stratégies d’interaction basées sur des capteurs IMU, puis analysons les entretiens. Ensuite, nous proposons PLaTune, une méthode supervisée de désintrication basé sur un modèle flow matching, qui restructure l’espace latent en un espace de contrôle désintriqué défini par l’utilisateur, permettant d’ajouter des contrôles temporels à des modèles préentraînés. Enfin, nous proposons de définir les contrôles implicitement à partir de variations au sein de groupes d'exemples faiblement annotés. Nous formalisons cette idée dans un cadre général via un objectif d’apprentissage contrastif dans un espace de variation, capturant les différences relatives entre embeddings pour construire plusieurs vues du contrôle cible. L'appliquant aux autoencodeurs variationnels, nous proposons le modèle CoALa, qui transforme directement l’espace latent préentraîné en un espace de contrôle personnalisé, désintriquant les caractéristiques ciblées avec peu d'annotations.