Neural Audio Synthesis of Realistic Piano Performances
![]()
Lenny Renault, doctorant de Sorbonne Université, a effectué sa thèse intitulée "Neural Audio Synthesis of Realistic Piano Performances" au laboratoire STMS (Ircam - Sorbonne Université - CNRS - Ministère de la Culture), au sein de l'équipe Analyse et synthèse du son, sous la direction d’Axel Roebel, responsable d’équipe, et le co-encadrement de Rémi Mignot, chercheur.
Sa thèse a bénéficié du financement du Projet Européen Horizon 2020 n°951911 - AI4Media.
La soutenance aura lieu en anglais, dans la Petite Salle du Centre Pompidou, le lundi 8 juillet 2024 à 15h00. Elle sera retransmise en direct sur https://www.youtube.com/
Il est demandé au public d'entrer par la plazza du Centre Pompidou, au niveau de l'entrée "File rouge".
Le jury sera composé de :
- Mark Sandler, Queen Mary University of London, Rapporteur
- Mathieu Lagrange, CNRS, Laboratoire des Sciences du Numérique de Nantes (LS2N), Rapporteur
- Gaël Richard, Laboratoire Traitement et Communication de l'Information (LTCI) - Télécom Paris, Examinateur
- Jesse Engel, Google DeepMind, Examinateur
- Juliette Chabassier, Modartt, Examinatrice
- Axel Roebel, STMS Lab, Directeur de thèse
Résumé : Musicien et instrument forment un duo central de l'expérience musicale. Indissociables, ils sont les acteurs de la performance musicale, transformant une composition en une expérience auditive émotionnelle. Pour cela, l'instrument est un objet sonore que le musicien contrôle pour retranscrire et partager sa compréhension d'une oeuvre musicale. Accéder aux sonorités d'un tel instrument, souvent issu de facture poussée, et à la maîtrise de jeu, requiert des ressources limitant l'exploration créative des compositeurs.
Cette thèse explore l'utilisation des réseaux de neurones profonds pour reproduire les subtilités introduites par le jeu du musicien et par le son de l'instrument, rendant la musique réaliste et vivante. En se focalisant sur la musique pour piano, le travail réalisé a donné lieu à un modèle de synthèse sonore pour piano ainsi qu'à un modèle de rendu de performances expressives.
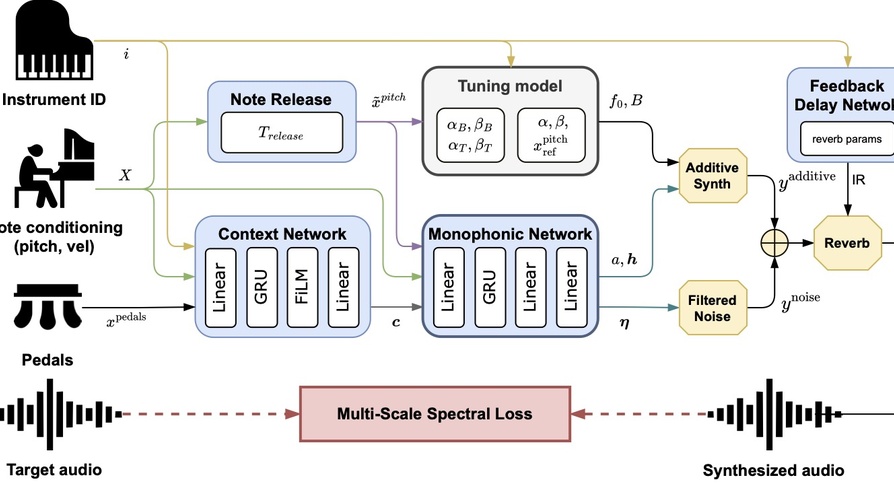
DDSP-Piano, le modèle de synthèse de piano, est construit sur l'approche hybride de Traitement du Signal Différentiable (DDSP) permettant d'inclure des outils de traitement du signal traditionnels dans un modèle d'apprentissage profond. Le modèle prend des performances symboliques en entrée, et inclut explicitement des connaissances spécifiques à l'instrument, telles que l'inharmonicité, l'accordage et la polyphonie. Cette approche modulaire, légère et interprétable synthétise des sons d'une qualité réaliste tout en séparant les différents éléments constituant le son du piano.
Quant au modèle de rendu de performance, l'approche proposée permet de transformer des compositions MIDI en interprétations expressives symboliques. En particulier, grâce à un entraînement adverse non-supervisé, elle dénote des travaux précédents en ne s'appuyant pas sur des paires de partitions et d'interprétations alignées pour reproduire des qualités expressives.
La combinaison des deux modèles de synthèse sonore et de rendu de performance permettrait de synthétiser des interprétations expressives audio de partitions, tout en donnant la possibilité de modifier, dans le domaine symbolique, l'interprétation générée.